模型基本信息
词汇总量: 32064 词汇表大小为 32064 意味着这个模型可以处理 32064 个不同的 tokens embedding_length: 3072 padding_idx: 32000

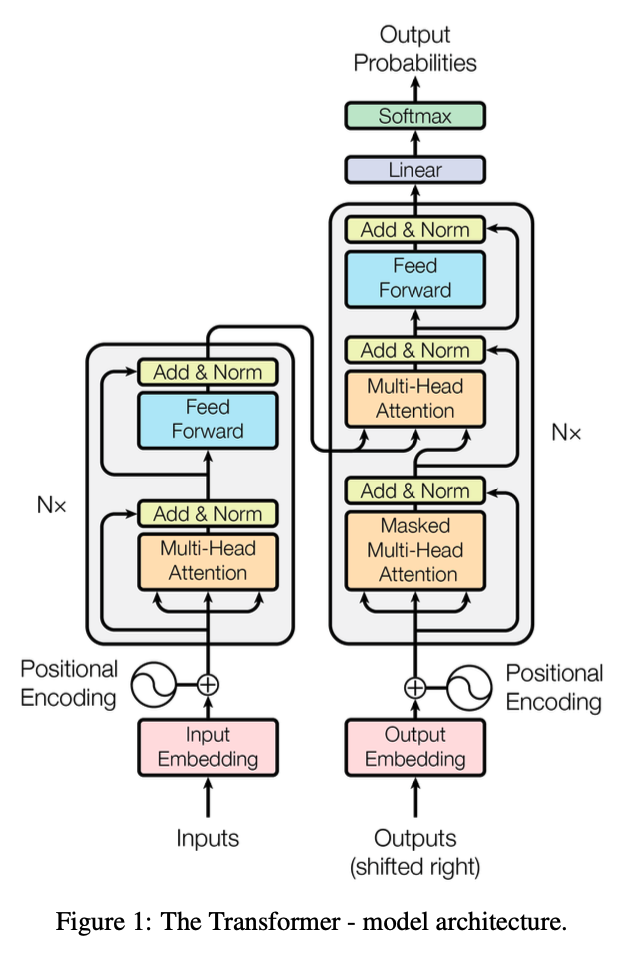
Transformer 架构
Embedding 层
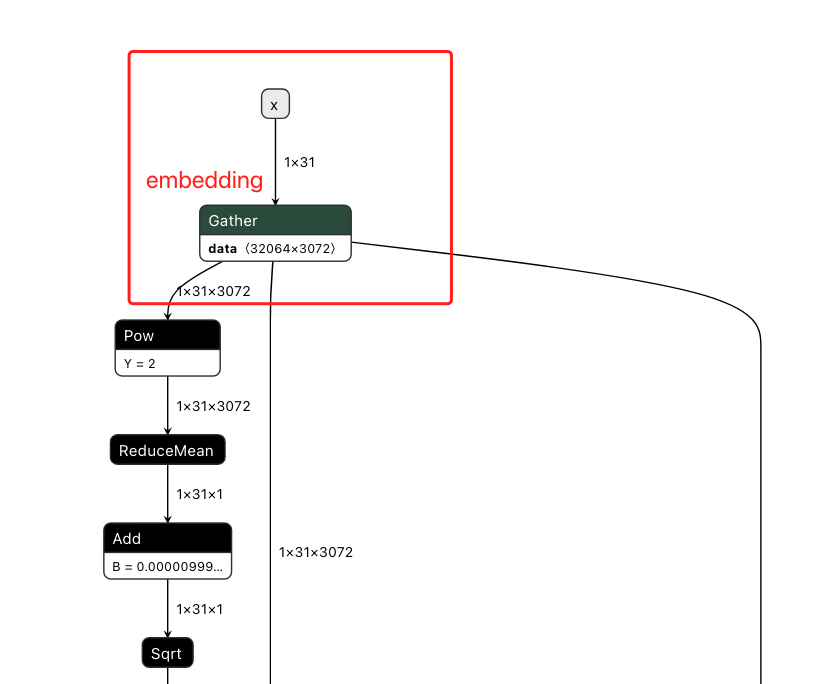
主要是用 nn.Embedding 将输入的整数序列转换为密集的向量表示.
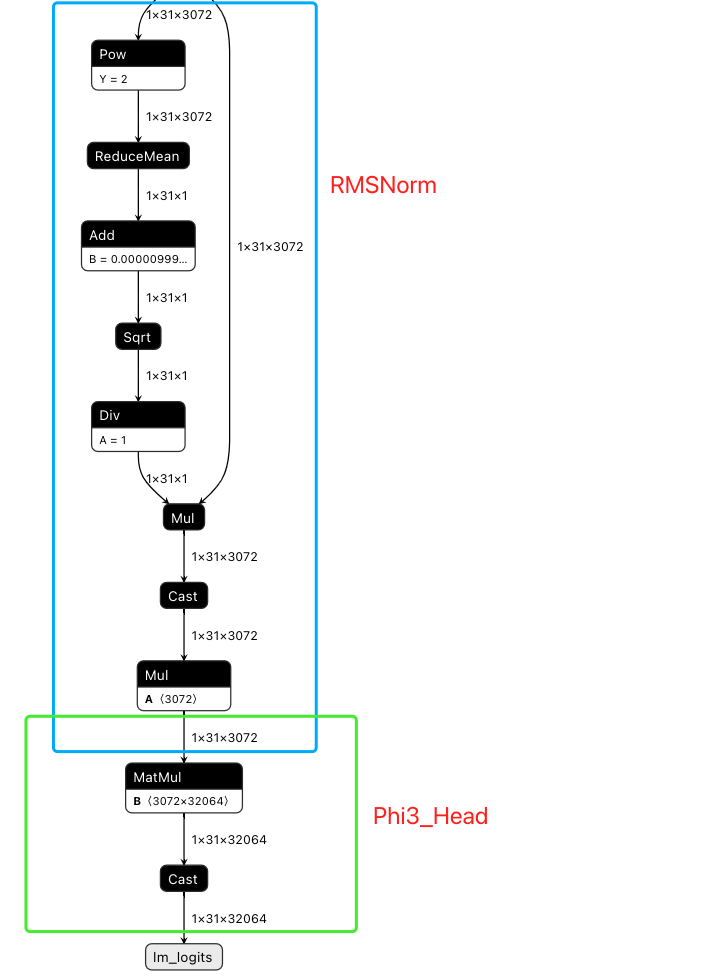
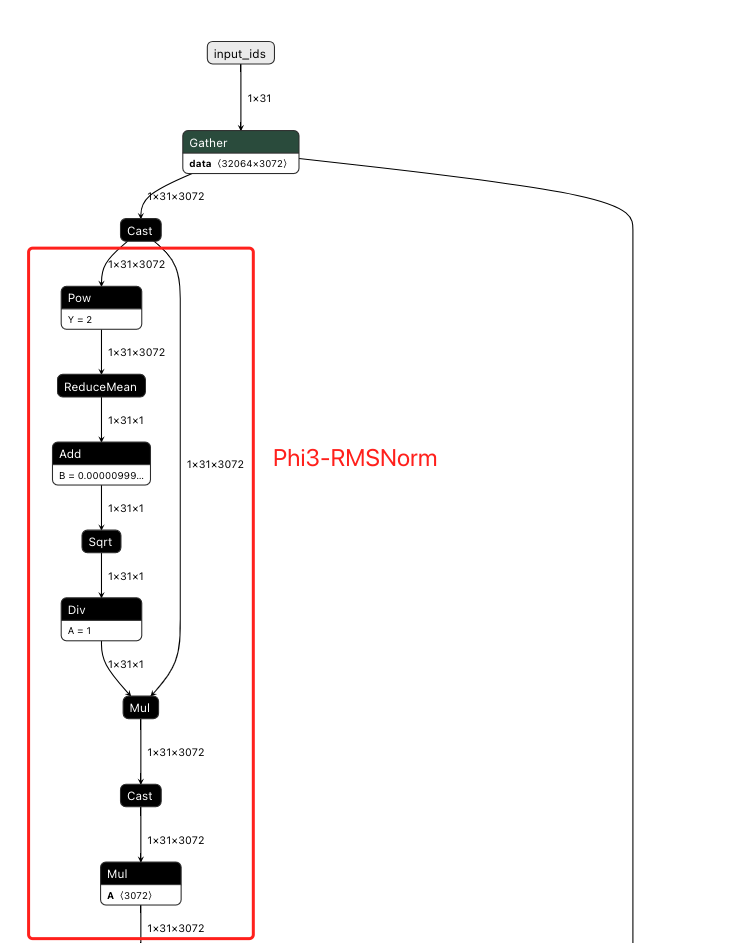
RMSNorm 归一化层
减少网络各层之间的数据分布差异, 提升模型的训练效率和稳定性.
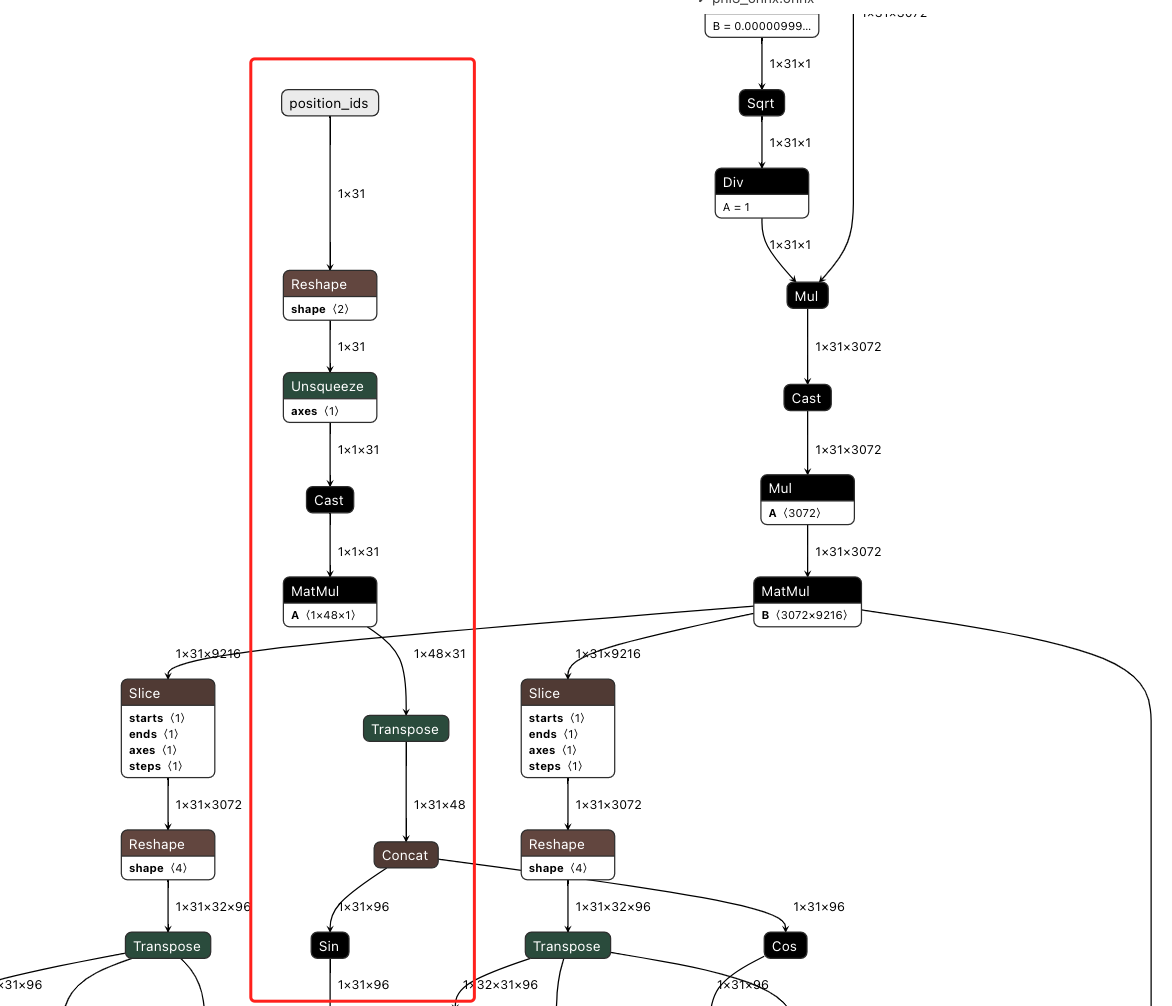
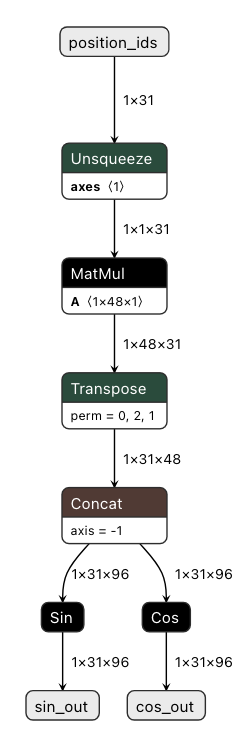
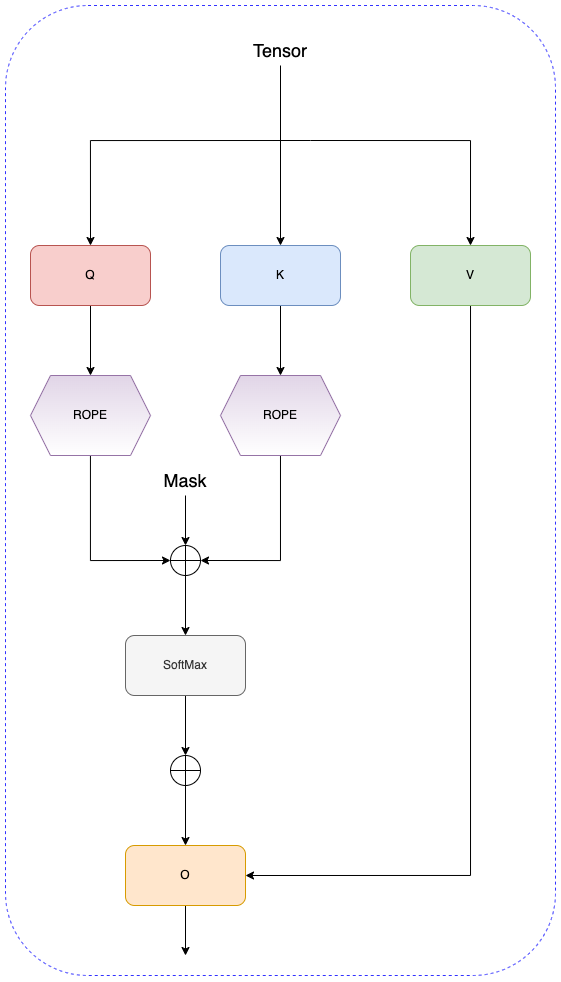
RoPE 层
一种相对位置编码技术, 区别于绝对位置编码 (计算位置编码后直接加到输入 tensor 上)
RoPE 能利用上 token 之间的相对位置信息
ONNX-0 ONNX-1
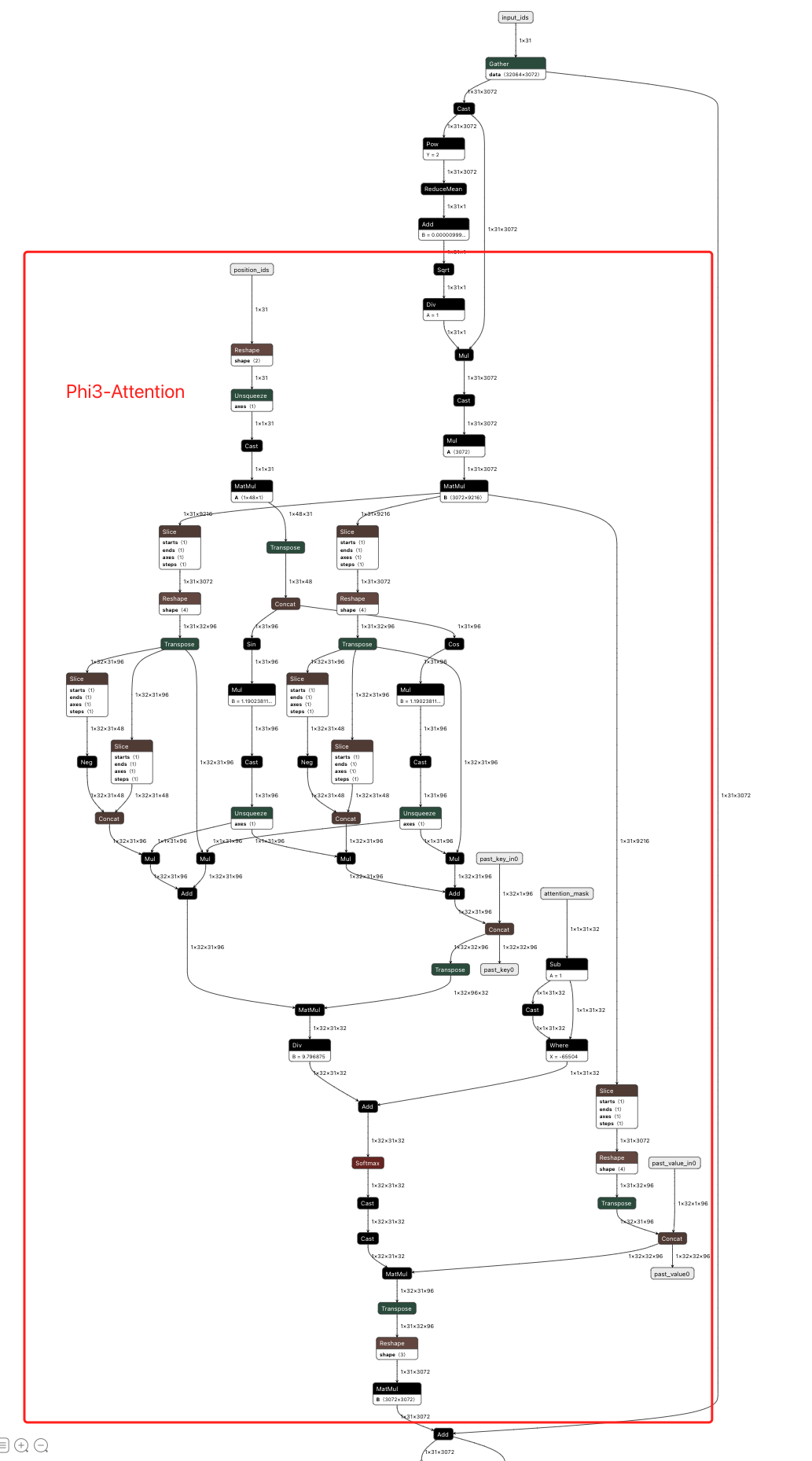
Attention 层
Phi3-MLP, 一种改进的 MLP,结合了门控机制和升降维操作, 增强了非线性建模能力和动态控制能力
动态建模能力:
通过门控分量 gate 动态调整 up_states,使网络能够根据输入调整特征的重要性。 非线性表示增强:
使用激活函数 activation_fn 和门控机制,提升模型的非线性表达能力。 高效计算:
升维后操作非线性激活,再降维,这种设计常用于在保持参数量较低的情况下提升表示能力。
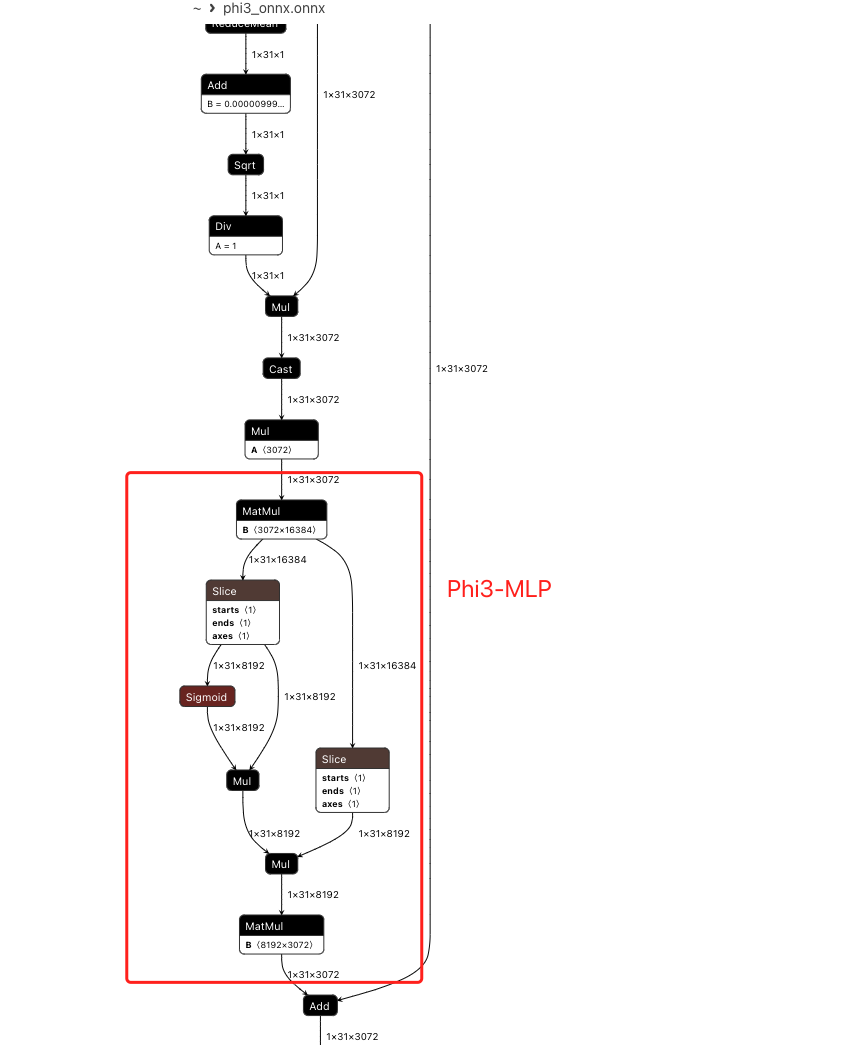
DecoderLayer
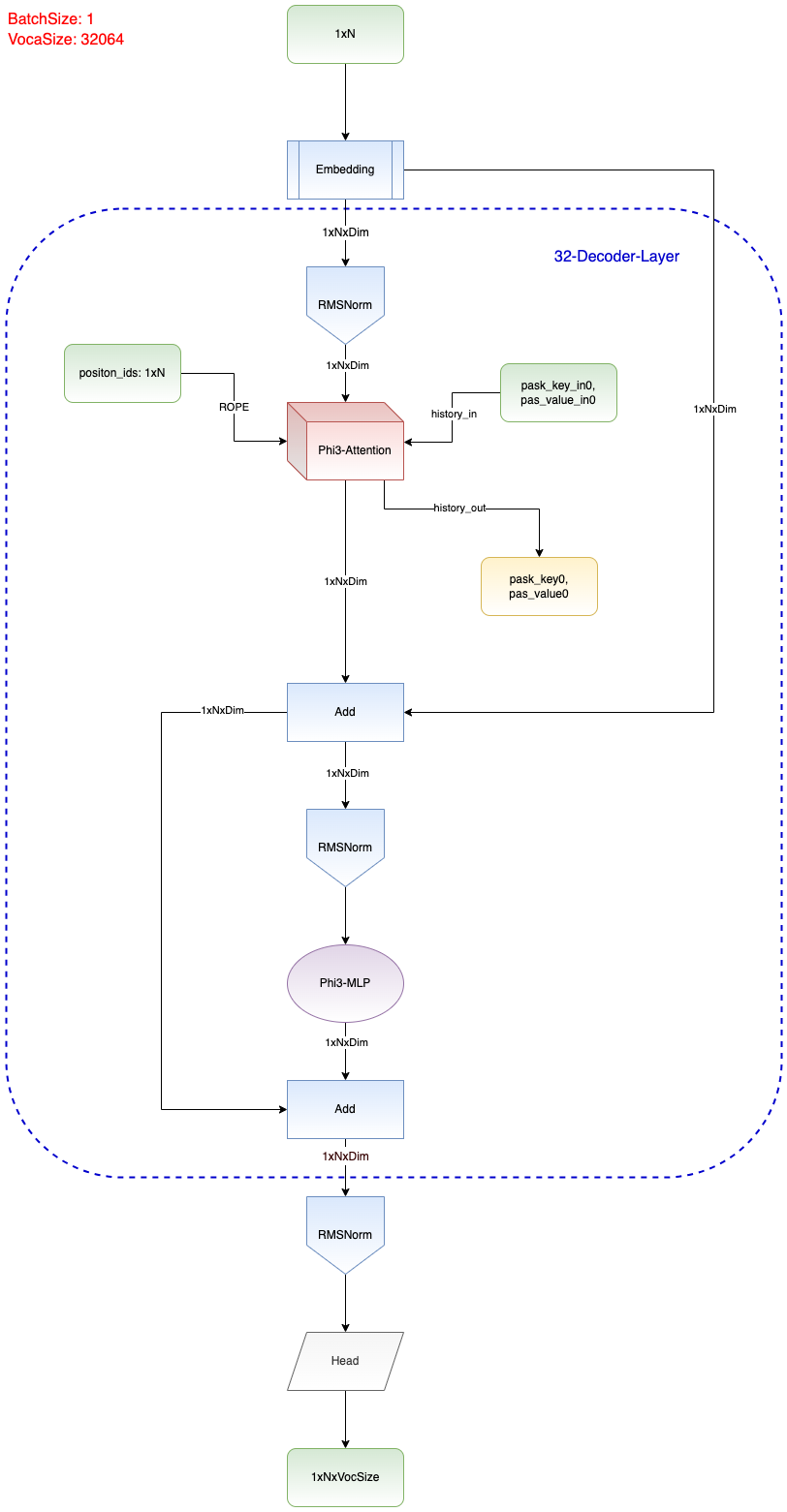
模型整体简化版结构
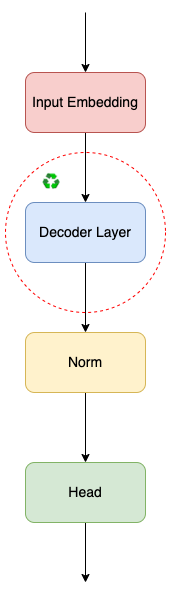
Decoder Layer 简化版结构

Attention-Simple-Arch
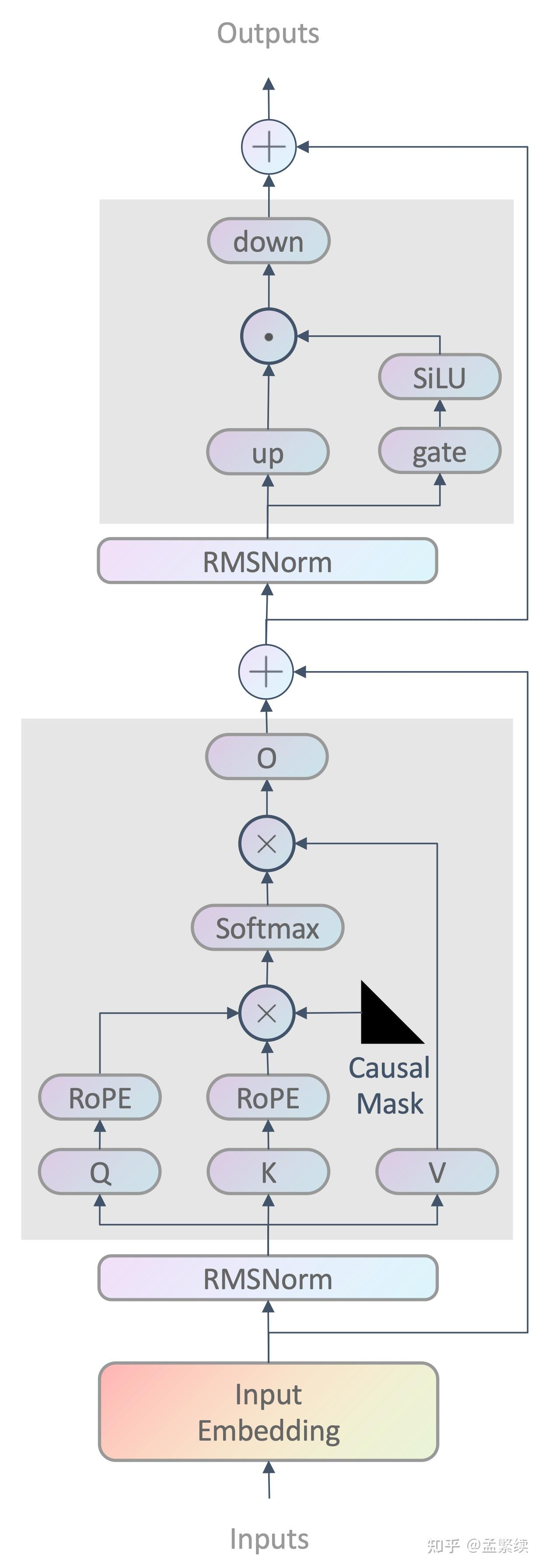
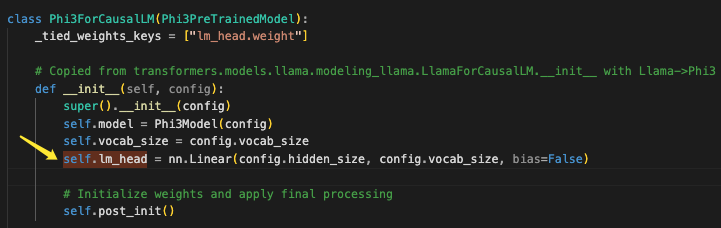
Head 层
Linera 层, 转换为 onnx 之后是一个 (N, 3072) 和 (3072, 32064) 的 matmul, 得到 32064 的概率
ONNX CODE