huggingface: https://huggingface.co/OpenGVLab/InternVL2_5-1B
关于 ViT 的介绍参考: https://blog.csdn.net/lsb2002/article/details/135320751
将图像分为多个 patch 之后, 还需要将其编码为 token, 在代码实现上, 就是通过一个 Conv 来实现.
模型架构: ViT-MLP-LLM
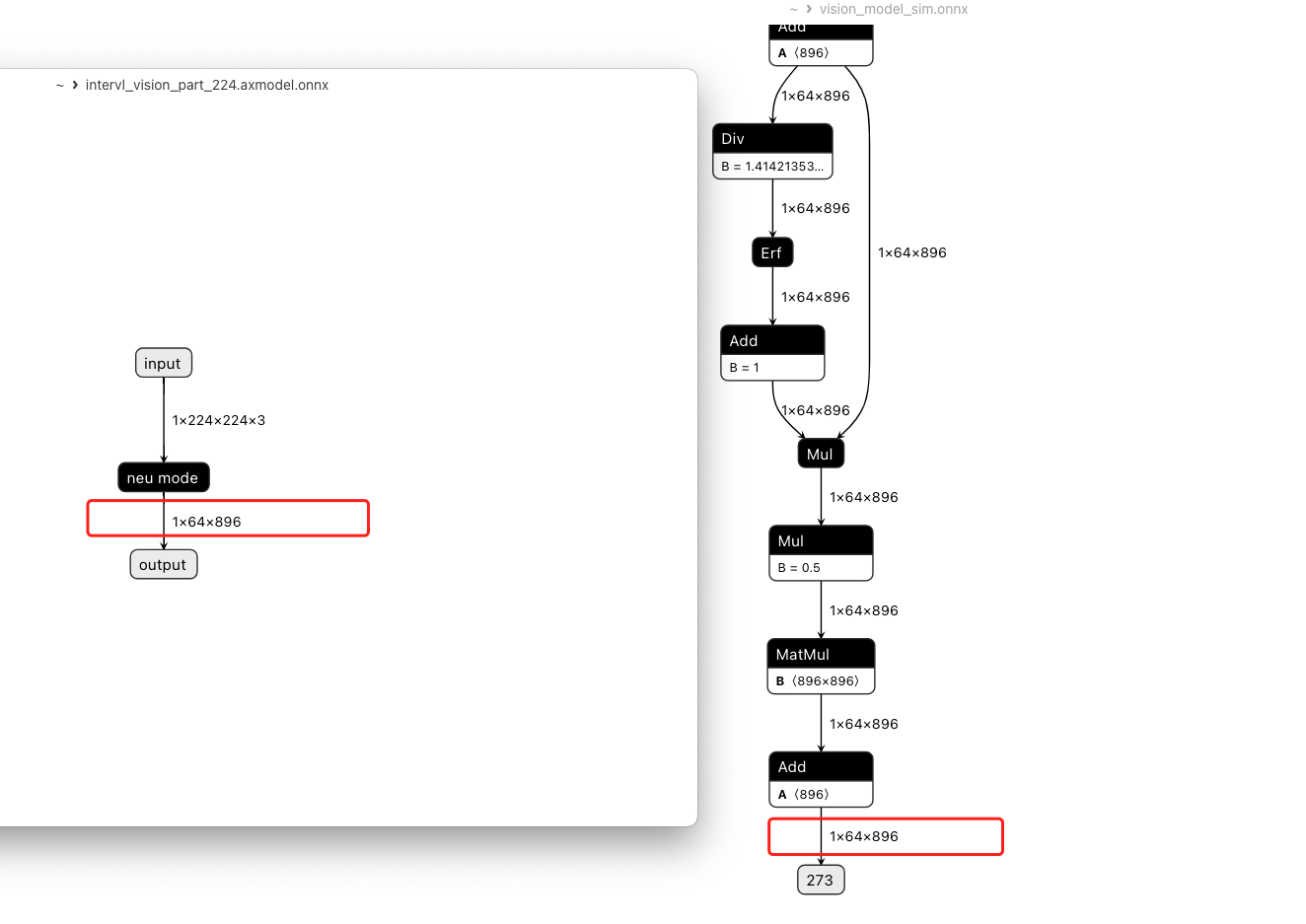
导出 vision-part onnx, 主要是 vit-encoder 部分 2025.01.15
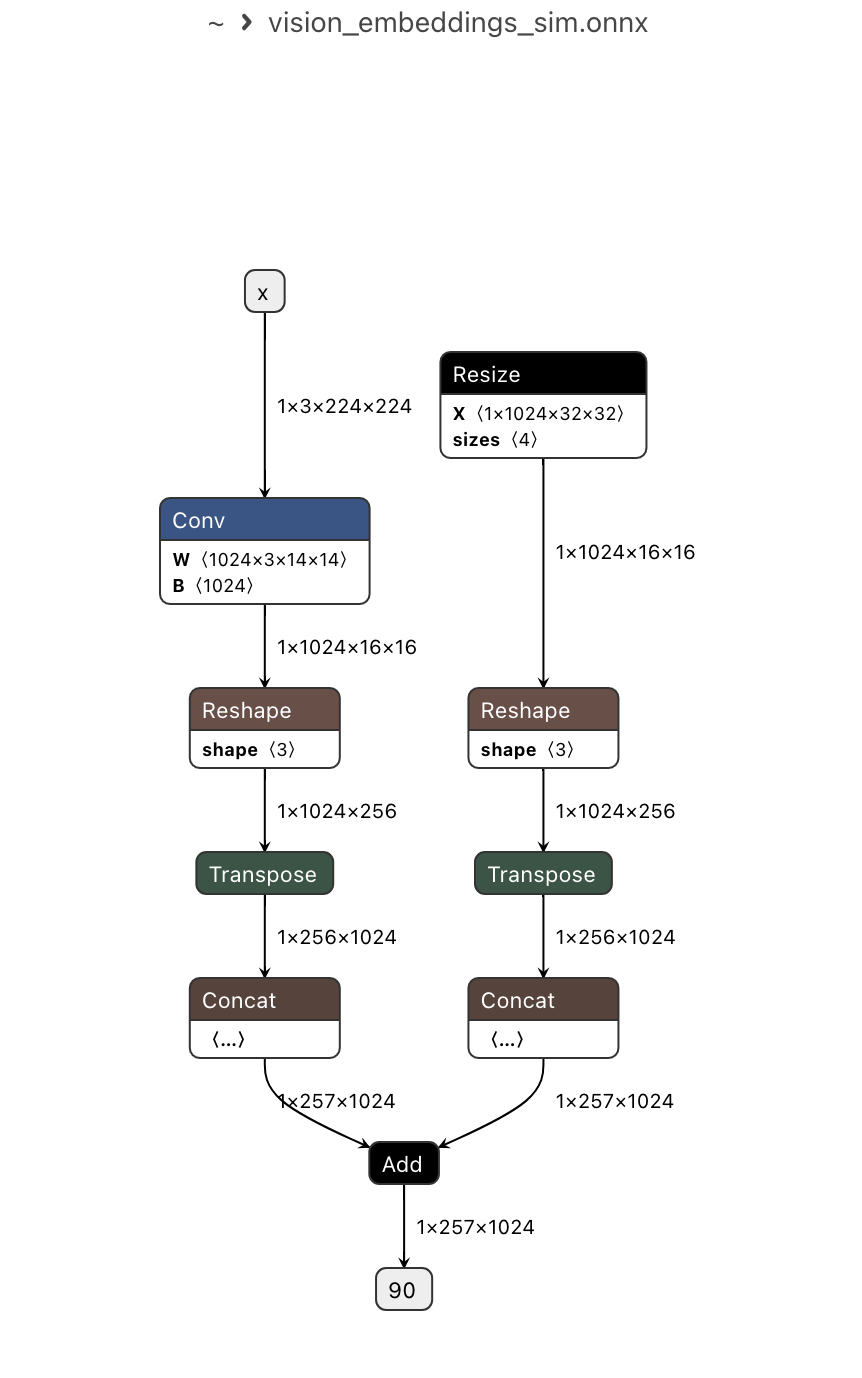
这部分 onnx 导出已经完成, InternVisionModel 包含两部分, 一个 embeddings, 一个 encoder
其中 embeddings onnx 结构如下:
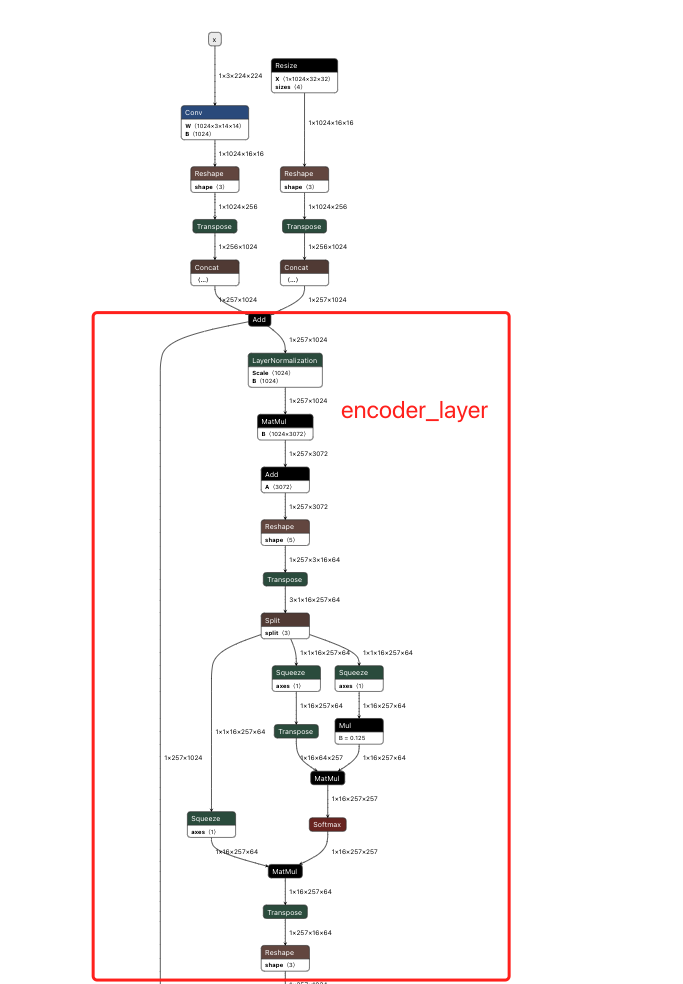
下面是 encoder layer
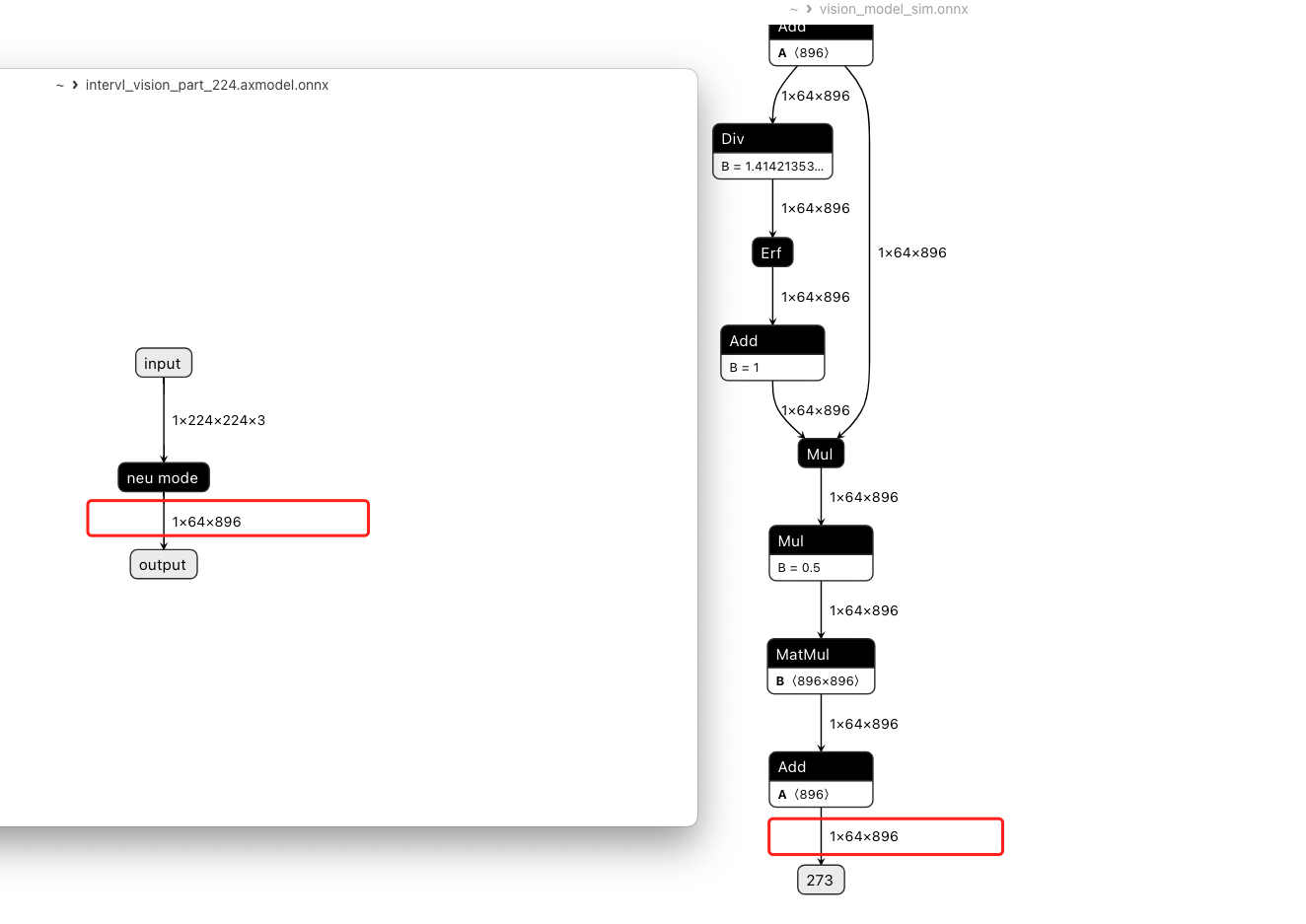
vision-model 后面还需要加一些处理后通过 mlp 最后输入 llm
2025.01.16 任务安排调整
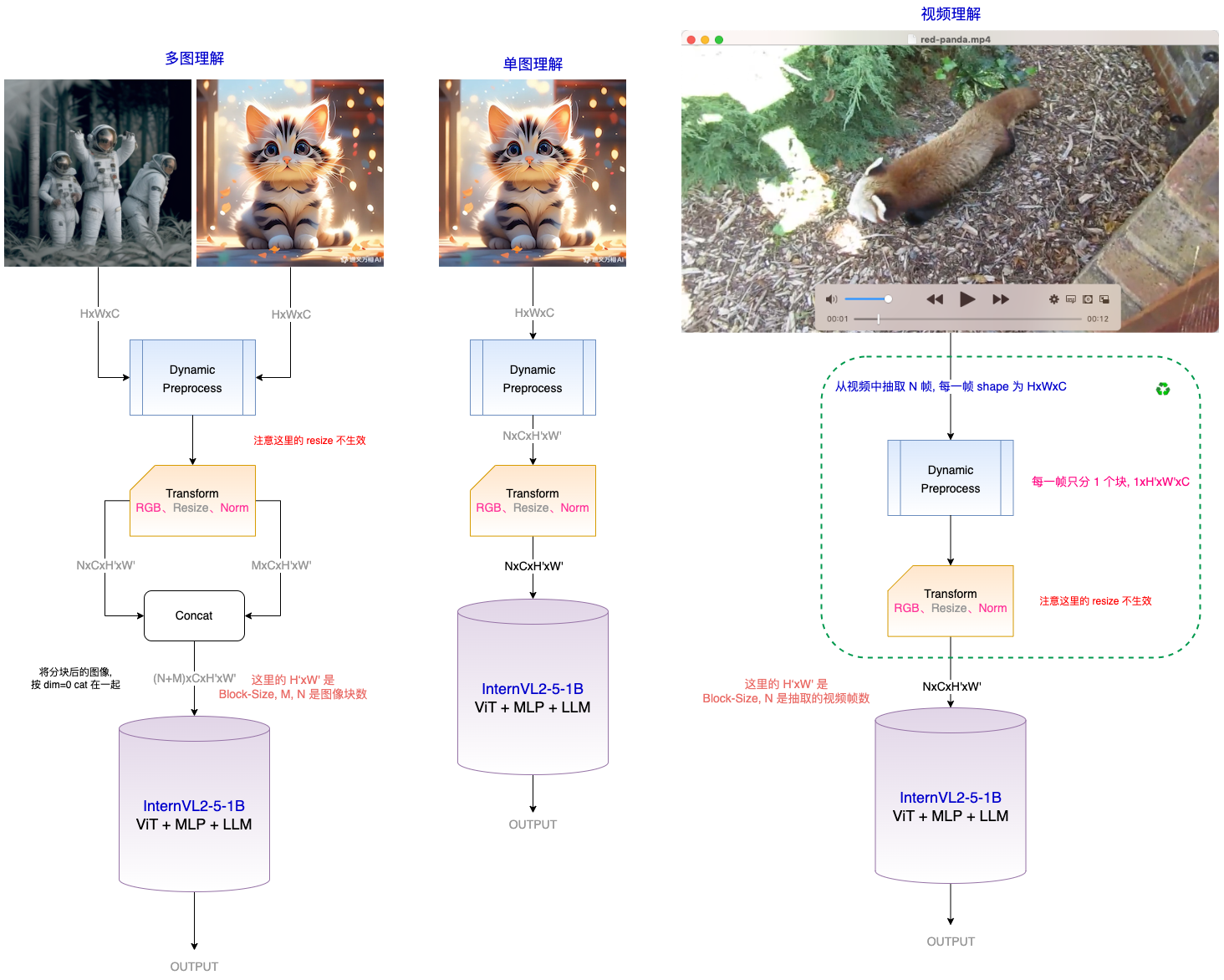
InternVL2_5-1B 看看视频理解是怎么做的,与目前单张图片(448*448)理解的,在 pipeline 上有什么差异
节后出一个视频理解的 DEMO
pipeline 走通, 模型理解视频的效果还不错!
视频理解和图像理解的区别在于数据预处理
多卡推理 78B 模型
按照官方给的 code 执行后, 代码会报错, 原因似乎在于 qwen 的模型脚本中有 bug, 会出现 un-same devices 的错误, 在 /home/baiyongqiang/miniforge-pypy3/envs/hf/lib/python3.9/site-packages/transformers/models/qwen2/modeling_qwen2.py#157 行中添加了 .to(x) 后绕过该错误, 可以正常运行.
1
2
3
4
5
6
7
8
9
10
11
device_map = split_model('InternVL2_5-78B') # 多卡运行
# device_map = "auto" # 可以多卡, 效果同上
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map=device_map).eval() # .cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)