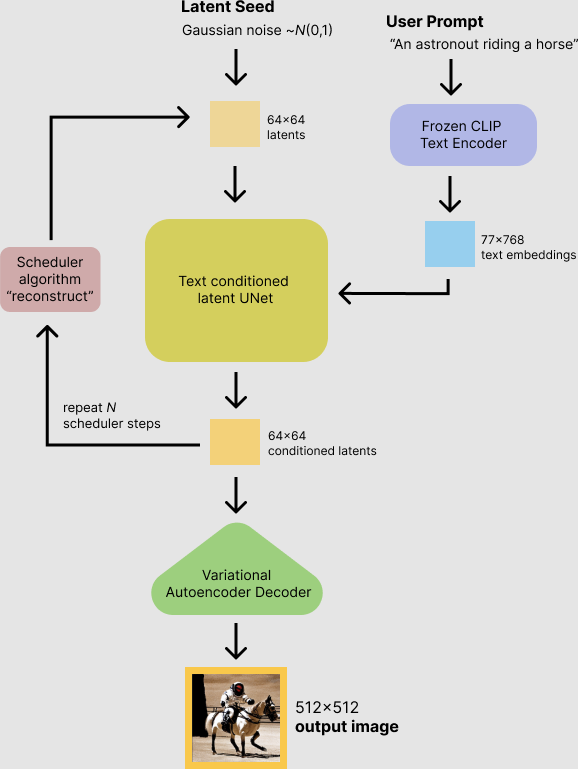
模型流程如下:
用户输入 prompt, latent 可以是 noise 也可以是输入图像经过 vae-encoder 后的得到的 latent, 中间经过 unet, 最后经过 vae-decoder 获取图像输出 code: https://github.com/skylake5200/sd1.5-lcm.axera
expected {‘tokenizer’, ‘text_encoder’, ‘safety_checker’, ‘vae_encoder’, ‘unet’, ‘feature_extractor’, ‘scheduler’, ‘vae_decoder’}
but only {‘tokenizer’, ‘text_encoder’, ‘safety_checker’, ‘vae_encoder’, ‘unet’, ‘feature_extractor’, ‘scheduler’, ‘vae_decoder’}, 红色标记 为缺失项.
导出 vae onnx, 用于 image to image, 然而生成的图像却不同于之前的 pipeline 结果
Pipeline 结果

onnx 推理结果 (debug 之后发现只用了 prompt, 输入的图像没有用到), 这里的 onnx-infer 沿用了 text-to-image

图像处理逻辑不对, 输出结果如下
 vae.encoder 结果基本对的上, 重新 fix 了 timestep 的数值, 结果如下 (unet 部分对输入的修改逻辑不同, 需要 debug)
vae.encoder 结果基本对的上, 重新 fix 了 timestep 的数值, 结果如下 (unet 部分对输入的修改逻辑不同, 需要 debug)
 代码对齐 (主要是 unet 部分数据处理部分对齐, unet 使用未对 t 进行预计算的 onnx)
代码对齐 (主要是 unet 部分数据处理部分对齐, unet 使用未对 t 进行预计算的 onnx)
 使用预计算后的 t onnx 也可以获得正确结果
使用预计算后的 t onnx 也可以获得正确结果
 如果以 img2img 的 onnx-infer 代码执行 text-to-image 的话, 结果如下:
如果以 img2img 的 onnx-infer 代码执行 text-to-image 的话, 结果如下:

2025.01.15 目前不支持任意 size 输入?
onnx 是静态 shape, 需要将任意输入 resize 到 512x512 即可. 2025.01.23 导出 256x256 模型, 图生图 work.
支持导出任意 size, vae encoder 的输入 //8 z以后是 unet 的输入尺寸 导出 text encoder, 需要尝试降级 transformer 4.47.0.dev0 到 transformers==4.42.4, 可以成功导出, 绕过下面的 error.
Invoked with: %343 : Tensor = onnx::Constant(), scope: transformers.models.clip.modeling_clip.CLIPTextTransformer::/transformers.models.clip.modeling_clip.CLIPEncoder::encoder/transformers.models.clip.modeling_clip.CLIPEncoderLayer::layers.0/transformers.models.clip.modeling_clip.CLIPSdpaAttention::self_attn , ‘value’, 0.125