huggingface: https://huggingface.co/KwaiVGI/LivePortrait
github: https://github.com/KwaiVGI/LivePortrait
该模型是在 Face Vid2vid 的基础上进行了一系列的改进
模型输入:
source driving source others 模型结构:
appearance_feature_extractor: F
外观特征提取器: 将源图像映射到一个 3D 外观特征体积 输入 shape: 1x3x256x256 输出 shape: 1x32x16x64x64 其他: 3D Conv motion_extractor: M
输入 shape: 1x3x256x256 输出 shape: 7 个输出分支, 分别为 1x66 (pitch), 1x66 (yaw), 1x66 (roll), 1x3 (t), 1x63 (exp), 1x1 (scale), 1x63 (kp) 使用 ConvNeXt-V2-Tiny 作为骨干网络, 直接预测输入图像的规范关键点、头部姿态和表情变形
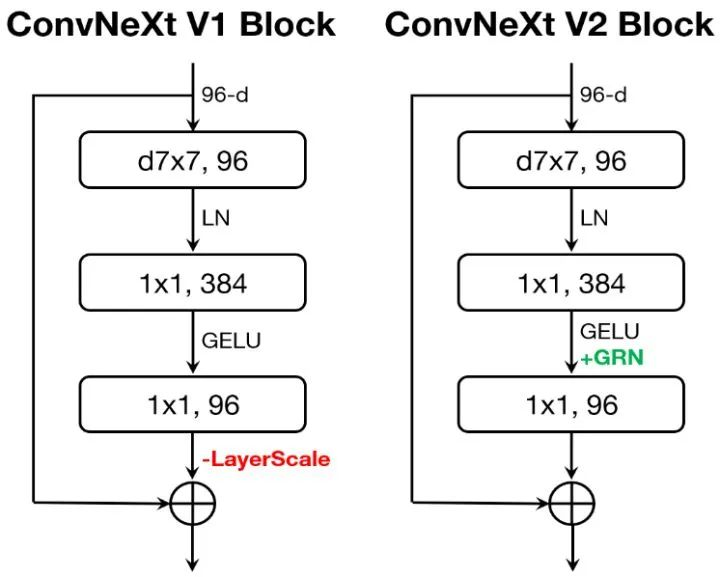
使用ConvNeXt-V2-Tiny作为主干网络, 直接预测输入图像的规范关键点、头部姿态和表情变形 将原始的规范隐式关键点检测器 L, 头部姿态估计网络 H 和 表情变形估计网络 \delta 统一为一个单一的模型 M 规范式关键点检测器 (L): 检测源图像的规范隐式关键点 头部姿态和表情变形: 通过头部姿态估计网络H 和 表情变形估计网络 \delta 来确定 warping_module: W
变形场估计器: 利用隐式关键点表示生成一个变形场, 并使用这个场来变形源特征体积 输入 shape: feature 3d: 1x32x16x64x64 kp_driving: 1x21x3 kp_source: 1x21x3 输出 shape: occlusion_map: 1x1x64x64 deformation: 1x16x64x64x3 out: 1x256x64x64 spade_generator: G
将 SPADE(一种方法)的解码器, 作为 LivePortrait 的生成器 G: 将变形后的特征通过解码器转换到图像空间, 生成目标图像 输入 shape: 1x256x64x64 输出 shape: 1x3x512x512 stitching_retargeting_module: S and R
输入 shape: 1x126 输出 shape: 1x65 拼接和重定向 stitching: 拼接模块的目的是将动画后的肖像无缝地贴回到原始图像空间, 例如在肩部区域避免像素错位. 这允许处理更大的图像尺寸和同时动画化多张面孔. 在训练过程中, 拼接模块接收源图像和驱动图像的隐式关键点作为输入, 并估算出驱动关键点的变形偏移量. 然后, 使用这个偏移量更新驱动关键点, 并生成预测图像. retargeting: 眼睛重定向模块: 设计用于解决跨身份再现 (cross-id reenactment) 时眼睛闭合不完整的问题, 特别是当小眼睛的人驱动大眼着的人时. 嘴唇重定向模块: 设计原理与眼睛重定向模块类似, 确保输入时嘴唇处于闭合状态, 以便于更好的动画驱动. 使用小型多层感知器 (MLP) 网络来实现重定向, 因为它们具有足够的能力来学习所需的控制效果, 同时保持计算效率
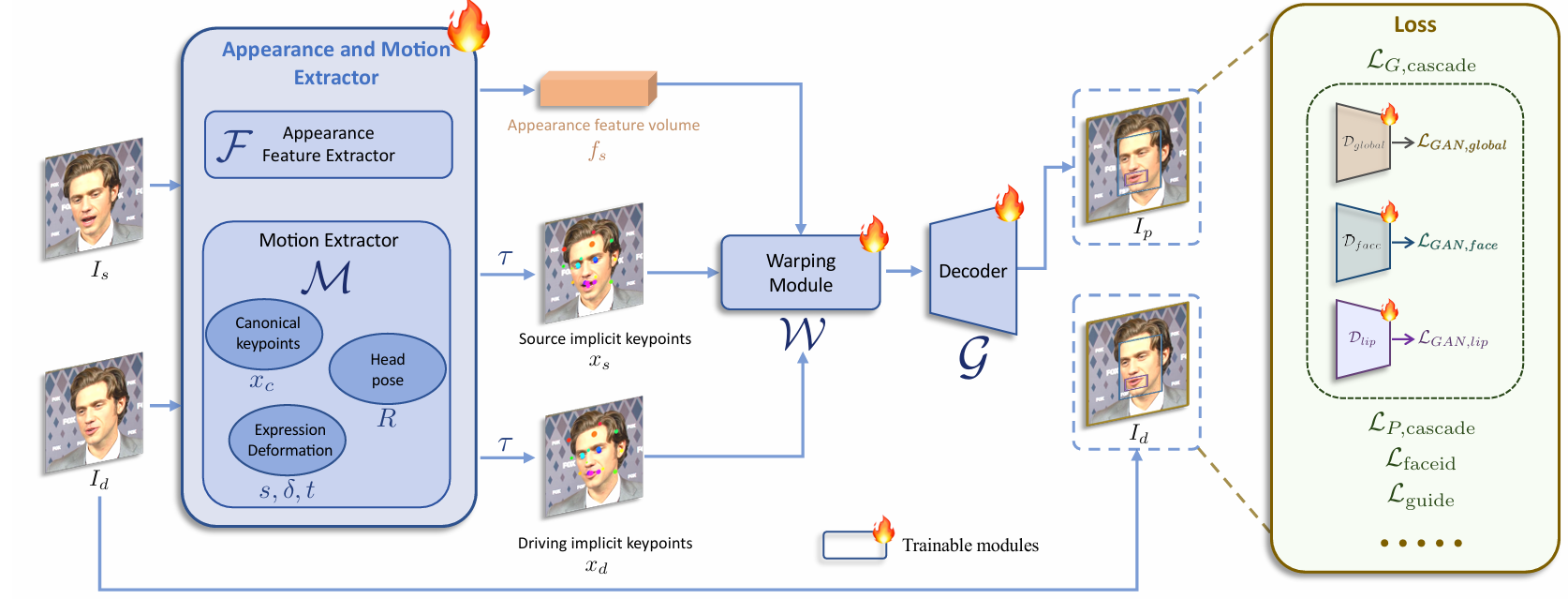 推理阶段是模型将源图像和驱动视频序列转换成动画输出的过程.
推理阶段是模型将源图像和驱动视频序列转换成动画输出的过程.
这一过程包括特征提取、关键点转换、拼接和重定向模块的应用,以及最终图像的生成:
特征提取: 首先源图像中提取特征体积 Fs 和 规范隐式关键点 Xc, s 运动提取: 对于驱动视频序列的每一帧, 提取运动参数 sd, i、\sigma-d, i、td, i 和 头部姿态 Rd, i 关键点转换: 根据源图像和驱动视频参数, 转换源和驱动隐式关键点 xs 和 xd, i 拼接和重定向: 根据需要, 应用拼接模块和眼睛及嘴唇重定向模块. 这些模块可以根据指示变量 αst、αeyes 和 αlip 来决定是否激活相应的功能 图像生成: 最终, 使用变形网络 W 和解码器 D 生成预测图像 Ip,i 2024.01.24 15:00
- 当前进度, ort 的代码还没有写, 几个模块大致梳理清楚了, 年后回来就把下面这个 execute 函数展开写成 ort 推理就好
2025.02.08
涉及 5 个 ONNX 模型, 它们分别执行不同的任务:
appearance_feature_extractor: 提取源图像 (source) 的外观特征 (3D 特征) motion_extractor: 提取驱动视频 (driving) 的关键点运动信息 warping_module: 利用运动信息对源图像进行形变 spade_generator: 生成最终的动画化头像 stitching_retargeting_module: 将不同部分的图像拼接、调整,使最终动画更加自然 motion_extractor 用来提取 头部关键点、姿态、表情信息 (outs 是模型输出结果):
1
2
3
4
5
6
7
8
9
kp_info = {
'pitch': torch.from_numpy(outs[0]),
'yaw': torch.from_numpy(outs[1]),
'roll': torch.from_numpy(outs[2]),
't': torch.from_numpy(outs[3]),
'exp': torch.from_numpy(outs[4]),
'scale': torch.from_numpy(outs[5]),
'kp': torch.from_numpy(outs[6])
}
其中:
pitch, yaw, roll: 头部旋转角度 (欧拉角可以转换为旋转矩阵) t: 平移量 exp: 表情变形量 scale: 缩放因子 kp: 关键点坐标 transform_keypoint 函数利用运动信息变换关键点坐标:
先计算旋转矩阵 rot_mat 关键点 kp 乘 rot_mat 进行旋转变换 加上 exp (表情变形) 乘以 scale (缩放) 关键点 x, y 加上 t (位移) make_motion_template 用于生成运动模板, 用于后续动画合成, 主要包括:
motion: 关键点运动数据 (旋转、位移、表情等) c_eyes_lst & c_lip_lst: 眼睛和嘴唇闭合程度, 用于嘴型匹配和眼睛眨动 其他补充.
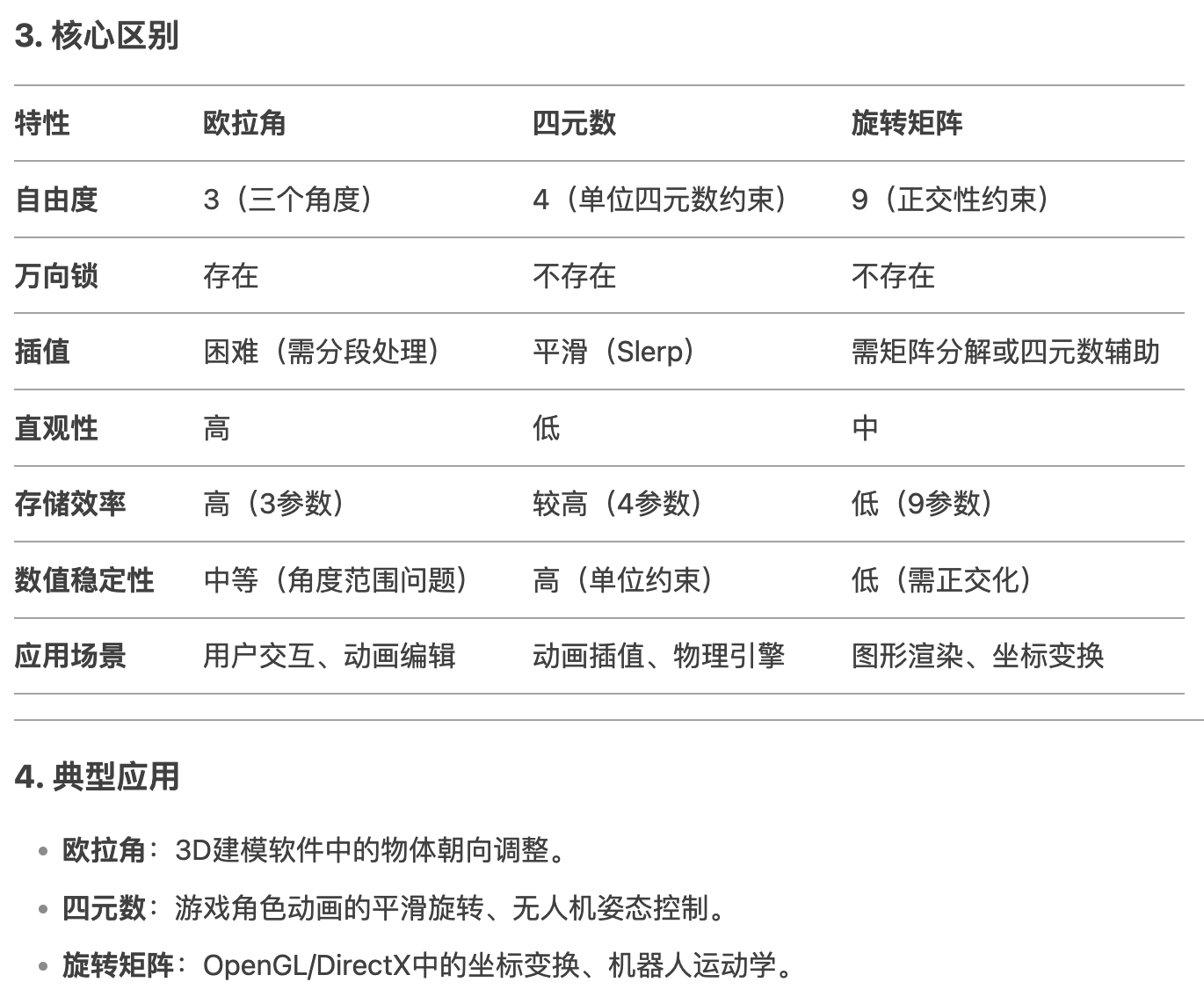
欧拉角、四元数以及旋转矩阵 (是描述三维旋转的三种常用方法, 可以相互转换)
欧拉角: roll-pitch-ywa 横滚-俯仰-偏航, 分内旋(绕物体自身轴)和外旋(绕固定轴), 优点是直观容易理解, 缺点是存在 “万象锁” 问题, 即当中间旋转为 90度 时失去自由度, 插值不平滑 四元数: 由标量 w 和 向量 (x, y, z) 组成, 形式为 q = w +xi + yj + zk, 需要满足单位长度 (w^2 + x^2 + y^2 + z^2 = 1). 优点是无万象锁, 插值平滑, 效率高, 缺点是抽象, 不直观. 旋转矩阵: 3x3 矩阵. 优点是数学基础严谨, 缺点是参数冗余, 数值误差累积需要重新正交化.
数据处理
source 图像 rgb, resize & limit, 然后 crop 出头部位置, resize 到 256x256, 除以 255 做归一化 这个头像同样需要计算 头部姿态和表情等信息 这个头像就是 appearance_feature_extractor 外观特征提取器的输入 driving 图像(视频), 主体一般只有头部 先以 rgb 格式读取, 然后 resize 到 256x256x3 的 size, 然后做 fp32 的归一化, 除以 255 并 clip 至 0~1 之间 然后就可以用 driving 以及 eye 相关数据创建运动模板 使用 motion_extractor 模块, 读入 driving (1x3x256x256) 然后计算出头部姿态以及表情、缩放等信息 (某些 tensor 的输出会走后处理得到确切的值), 保存在一个 x_i_info 的 dict 中 然后 transformer_keypoint 函数会吃 x_i_info 数据, 计算出一个 tensor (1x21x3), 主要公式可能为: k’ = s · (R·k + exp) + t 我之前的疑问是: 既然 kp_info 是从一幅图像上得到的 kp, exp, roll, pitch, yaw 等信息, 那最后为什么还要把这些数据乘在一起呢?. 问了 gpt, 它表示 kp 并非直接从输入图像上预测出来的, 而是某个标准人脸模型的关键点, 而乘法的原因就是将标准关键点转换为输入图像中的真实关键点.