1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# audio.mp3 -> log_mel 计算过程
# lib/python3.9/site-packages/transformers/models/whisper/processing_whisper.py#69
inputs = self.feature_extractor(audio, *args, sampling_rate=sampling_rate, **kwargs)
# 下面是 feature_extractor 的具体实现过程
# 其中 audio 是 librosa.load 在 sampling_rate=16k 的结果, 目前 shape 为 (2862144,)
# self.feature_extractor -> lib/python3.9/site-packages/transformers/models/whisper/feature_extraction_whisper.py(248)
raw_speech = [np.asarray([raw_speech]).T] # raw_speech[0].shape (2862144, 1)
batched_speech = BatchFeature({"input_features": raw_speech})
padded_inputs = self.pad(batched_speech, padding=padding, ...) # 282
# padded_inputs.input_features[0].shape (480000, 1)
input_features = padded_inputs.get("input_features").transpose(2, 0, 1) # (1, 1, 480000)
input_features = extract_fbank_features(input_features[0], device) # extract_fbank_features 可以是 torch 实现, 也可以是 numpy 实现, shape (1, 128, 3000)
padded_inputs["input_features"] = input_features
# return_tensors 'pt'
padded_inputs = padded_inputs.convert_to_tensors(return_tensors) # 转换后: [0.8952, 0.6014, 0.4266]; 转换前: [0.8951664, 0.6014253, 0.4266312]. 显示精度会有区别 torch.float32
# 最后转为 torch.float16 会有精度丢失
# fp32 [0.8952, 0.6014, 0.4266] -> fp16 [0.8950, 0.6016, 0.4265]
TODO: 实现音频到 梅尔图谱的计算, 2025.03.05 20.33
Whisper 30s 限制
Whisper 模型在训练时就将音频预先切分成大约 30 秒的片段,其原因主要有以下几点:
-
训练数据标准化
Whisper 使用了 680,000 小时的有监督数据,这些数据在预处理阶段被切分成固定长度的 30 秒音频片段。这样可以使模型在训练时始终看到相同长度的输入,方便学习从梅尔频谱到文本的映射,同时降低了模型输入长度不一带来的复杂性。citeturn0search11 -
Transformer 架构的计算限制
Whisper 的核心是基于 Transformer 的编码器-解码器架构。Transformer 的自注意力机制在计算时复杂度为 O(N²),其中 N 是时间步数。对于 30 秒的音频(经过转换后大约有 3000 个时间帧),已经是一个比较合理的序列长度;而更长的输入会显著增加内存消耗和计算负担,可能导致推理速度下降或内存不足。citeturn0search11 -
时间戳和连续性问题
长时间音频的连续输入可能导致时间戳预测不准确,甚至出现“幻觉”现象(例如重复、漂移等问题)。通过将音频切块处理,可以在每个片段内更好地控制和调整时间戳,最后再将各个片段的转录结果拼接起来,确保整体转录的准确性和连续性。citeturn0academia10
综上所述,30 秒的限制既符合训练数据的预处理方式,也兼顾了模型计算效率和转录效果,是 Whisper 设计上的一项折衷与优化。
梅尔频谱
梅尔频谱是一种将音频信号转换成频率图像的方法,它利用了人耳对不同频率的敏感程度。其主要步骤如下:
-
短时傅里叶变换(STFT)
将连续的音频信号分成小块(通常用25毫秒的窗口),对每一块进行傅里叶变换,得到局部的频谱信息。 -
梅尔滤波器组
通过一组设计好的滤波器(这些滤波器在低频部分更密集,高频部分更稀疏),将传统的线性频谱映射到“梅尔刻度”。这种刻度更加符合人耳对音高的感知,因为人耳对低频变化更敏感,而对高频变化不那么敏感。 -
取对数
对滤波器组输出的能量取对数,以获得对数梅尔频谱,这样可以更好地处理音频信号的动态范围。
最终得到的梅尔频谱图就是一个二维数组,其中一维表示时间,另一维表示梅尔频段,数值则代表各个频段在每个时间窗口内的对数能量。它在语音识别、音乐信息检索等任务中非常常用,因为它更好地反映了人类听觉系统的特点。citeturn0search11
采样
“重采样到 16,000 Hz”指的是把音频数据的采样率调整为每秒采集 16,000 个数据点。可以把它想象成这样一个例子:
假设你有一段音乐或讲话的录音,本来它是以 44,100 Hz 的采样率记录的,这意味着每秒钟录音设备捕捉了 44,100 个瞬间的声音信息,就像你用相机在每秒拍 44,100 张照片来记录一段视频。重采样就是把这段录音的“照片”数量减少到每秒 16,000 张。尽管你“丢弃”了一部分信息,但对于语音识别来说,16,000 个样本已经足够捕捉到人声中的主要特征。
这种调整有两个主要目的:
- 匹配模型要求:Whisper 模型在训练时使用的音频都是 16,000 Hz,因此输入模型的数据也需要统一成这个采样率。
- 降低计算量:较低的采样率意味着每秒的数据量更少,这可以减少模型计算时的负担,同时仍能保留语音中的关键信息。
通过重采样,你并不会让音频播放得变慢或者变快,只是减少了描述声音波形的“点”的数量,就像把一张高分辨率的图片压缩到较低分辨率一样。这样做既保证了模型能理解音频,又提高了计算效率。
流程
整个过程大致可以分为以下几个步骤:
- 音频加载与预处理
- 加载音频:首先,将 a.mp3 文件加载成原始音频信号(通常是一个一维的浮点数数组),这一步可以使用诸如 librosa 或 ffmpeg 等工具。
- 重采样:为了匹配 Whisper 模型的要求,音频会被重采样到 16,000 Hz(如果原始采样率不是 16kHz)。
- 特征提取——生成对数梅尔频谱图
- 短时傅里叶变换 (STFT):将连续的音频信号分成多个小窗口(通常约 25 毫秒一窗口,步长 10 毫秒),对每个窗口进行傅里叶变换,得到局部的频谱信息。
- 梅尔滤波器组:通过一组滤波器将线性频谱映射到梅尔刻度。人耳对低频更敏感,因此在低频区域滤波器更密集,高频区域则较稀疏。
- 取对数:将滤波器组输出的能量取对数,得到对数梅尔频谱图。最终,得到一个二维数组,其中一维代表时间步(例如 3000 个时间点,对于 30 秒的音频),另一维代表 80 个梅尔频段。
- 模型推理
- 输入编码:生成的对数梅尔频谱图作为输入传递给 Whisper 模型的 Transformer 编码器。模型内部首先经过两个卷积层(用以降低时间维度和提取局部特征),然后进入多个 Transformer 编码器块,生成一系列隐藏状态。
- 自回归解码:Transformer 解码器利用编码器输出以及之前生成的文本(包括特殊标记,如
<|startoftranscript|>等)自回归地生成后续的文本标记。这一过程会持续直到生成结束标记<|endoftranscript|>。
- 后处理
- 解码文本:生成的标记序列通过分词器(通常使用字节对编码,即 BPE)解码成自然语言文本,同时可能需要去掉一些特殊的控制标记。
- 时间戳处理(可选):如果启用了时间戳功能,模型会在文本中插入时间信息,后续可以根据这些时间戳实现字幕同步等应用。
综上,a.mp3 经过上述流水线后,从原始音频信号逐步转换为对数梅尔频谱图,再经过 Transformer 进行编码和自回归解码,最终输出一段转录的文本。这个过程充分利用了声学特征提取与强大的 Transformer 模型,从而实现高精度的语音转文本任务。citeturn0search11 citeturn0academia10
其他
⚠️⚠️ 注意这里的 30 秒输入限制
🌹🌹🌹 OpenAI Whisper-large-v3 是一个基于
Transformer架构的多语言语音处理模型, 支持语音识别 (ASR-Automatic Speech Recognition)、语音翻译、语种检测等任务.🔥🔥🔥
Whisper-large-v3通过编码器-解码器结构和多任务统一建模, 实现了高效的语音处理. 其输入为30 秒音频片段, 经过Fbank 特征提取和分层注意力计算, 最终输出带任务标记的文本序列.🌟🌟🌟 相比前代,
v3在数据规模、多语言鲁棒性和长音频处理上均有显著提升.
一、模型组成结构
1. 核心架构
采用经典的编码器-解码器结构,
编码器负责提取音频特征,解码器生成文本序列.
编码器和解码器均由多层自注意力机制 (Multi-head Attention) 和前馈神经网络 (FFN) 堆叠而成.
Encoder-Decoder Transformer
- 编码器层数:
Whisper-large-v3的编解码器层数均为32, 与v2版本相同. - 解码器任务控制: 通过特殊标记 (如
<|startoftranscript|>、<|translate|>) 指示任务类型(语音识别或翻译)和语种.
关键参数解析
-
通过配置文件可以清晰看到模型结构:
1 2 3 4 5 6 7 8 9
{ "encoder_layers": 32, // 编码器层数 "decoder_layers": 32, // 解码器层数 "encoder_attention_heads": 20, // 编码器每层的注意力头数 "decoder_attention_heads": 20, // 解码器每层的注意力头数 "d_model": 1280, // 输入/输出向量维度 "decoder_ffn_dim": 5120, // 解码器前馈网络隐藏层维度 "encoder_ffn_dim": 5120 // 编码器前馈网络隐藏层维度 }
编码器(Encoder)
- 层数: 32 层 Transformer 编码器层
- 每层结构:
- 多头自注意力: 20 个注意力头 (
encoder_attention_heads) - 前馈网络(FFN): 输入维度 1280 → 隐藏层维度 5120 → 输出维度 1280 (
encoder_ffn_dim) - 残差连接与层归一化: 每层均有残差连接和
LayerNorm
- 多头自注意力: 20 个注意力头 (
- 输入处理:
- 音频频谱 → 线性投影到 1280 维 (
d_model) - 添加正弦位置编码 (
sinusoidal positional embeddings)
- 音频频谱 → 线性投影到 1280 维 (
解码器(Decoder)
- 层数: 32 层 Transformer 解码器层
- 每层结构:
- 多头自注意力: 20 个注意力头 (
decoder_attention_heads) - 交叉注意力: 编码器输出与解码器状态的注意力交互
- 前馈网络(FFN): 结构同编码器 (
decoder_ffn_dim=5120)
- 多头自注意力: 20 个注意力头 (
- 输出生成:
- 自回归生成文本标记 (
vocab_size=51866) - 支持束搜索 (
num_beams) 和温度采样 (temperature)
- 自回归生成文本标记 (
结构对比与性能影响
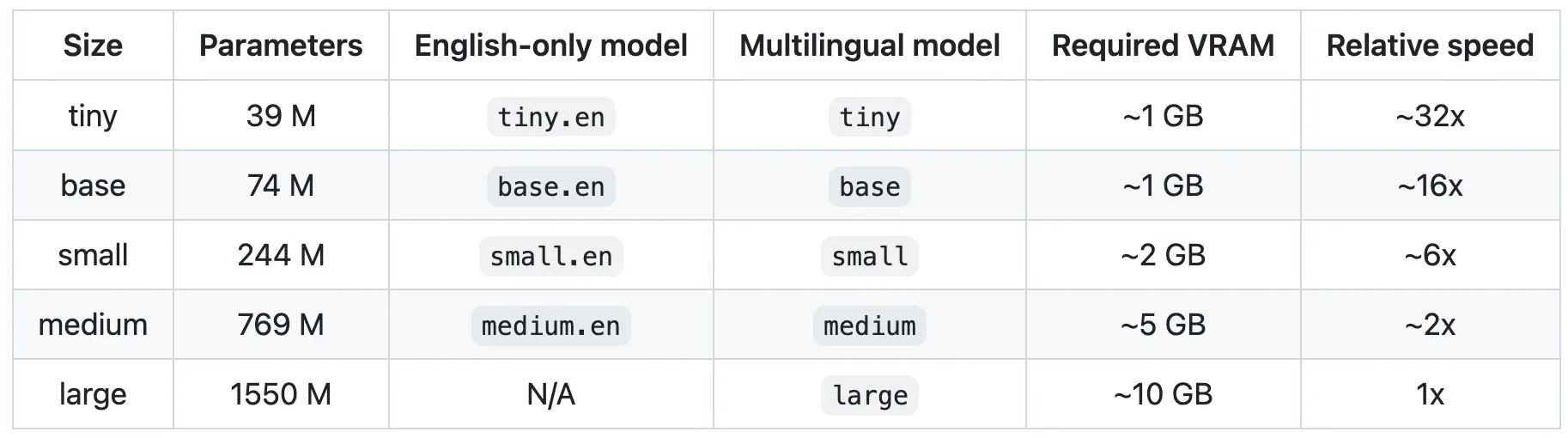
| 模型版本 | 编码器层数 | 解码器层数 | 参数量级 | 适用场景 |
|---|---|---|---|---|
| Whisper-tiny | 4 | 4 | ~39M | 移动端 |
| Whisper-base | 6 | 6 | ~74M | 实时识别 |
| Whisper-large-v3 | 32 | 32 | ~1.5B | 高精度转录 |
- 层数对性能的影响:
- 优势: 深层结构(32 层)能捕捉更复杂的声学-语言映射关系, 提升长音频和低信噪比场景的识别准确率.
- 代价: 更高的计算资源需求(需 16GB+ GPU 显存), 推理延迟增加约 3 倍(对比 base 版).
2. 输入特征
-
音频预处理:
- 重采样: 输入音频统一为
16kHz单声道格式. - 特征提取: 通过短时傅里叶变换 (
STFT) 生成80维Log-Mel频谱 (Fbank 特征), 帧长25ms, 帧移10ms. - 分段处理: 音频被切割为
30秒的片段, 不足部分补零.
- 重采样: 输入音频统一为
3. 输出结构
- 多任务输出标记: 解码器生成的文本序列包含四部分:
- 任务标记: 如
<|transcribe|>(转录) 或<|translate|>(翻译). - 语种标记: 如
<|zh|>(中文)、<|en|>(英语). - 时间戳标记(可选): 记录单词或音素的时间位置.
- 文本内容: 目标语言的转录或翻译结果.
- 任务标记: 如
二、工作流程
1. 输入阶段
- 音频输入限制: 支持常见音频格式 (如
WAV、MP3), 模型默认处理30秒内的音频. 长音频需外部工具 (如FFmpeg) 分割后分批输入. - 动态填充策略: 若输入音频短于
30秒, 自动填充静音段; 超过则截断或分块处理.
2. 中间处理过程
- 编码器特征提取:
- 分帧与频谱计算: 音频信号转为
80维Fbank特征. - 位置编码: 为特征序列添加位置信息, 增强时序建模能力.
- 多层 Transformer 编码: 通过自注意力机制捕捉长距离上下文依赖.
- 分帧与频谱计算: 音频信号转为
- 解码器生成逻辑:
- 任务引导: 初始标记指定任务 (如翻译为英语) 和语种.
- 自回归生成: 基于编码器输出和已生成标记, 逐步预测下一个文本标记.
- 束搜索(Beam Search): 优化生成质量, 平衡速度与准确性.
3. 输出阶段
- 后处理:
- 去标记化: 移除任务和语种标记, 保留纯文本.
- 时间戳对齐(可选): 若启用, 输出文本附带时间戳信息, 适用于字幕生成等场景.
- 多任务兼容: 同一模型可处理不同任务, 例如:
- 语音识别: 输入中文音频, 输出中文文本.
- 语音翻译: 输入中文音频, 输出英文文本.
三、应用场景示例
使用
Python调用OpenAI Whisper-large-v3模型进行语音识别, 可以通过openai-whisper库或Hugging Face的transformers库实现.
1. 通过 openai-whisper 进行语音识别
安装依赖
1
2
$ pip3 install openai-whisper
$ pip3 install torch # 如果没有 torch, 请安装 PyTorch(支持 GPU 加速)
代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import whisper
# 加载模型(自动下载或指定本地路径)
# 模型文件直接下载链接(推荐使用迅雷下载): https://openaipublic.azureedge.net/main/whisper/models/e5b1a55b89c1367dacf97e3e19bfd829a01529dbfdeefa8caeb59b3f1b81dadb/large-v3.pt
model = whisper.load_model("large-v3", device="cuda")
# 输入音频并指定任务
result = model.transcribe(
"./test_audio.mp3",
task="transcribe", # 可选 "transcribe" 或 "translate"
language="zh", # 指定输入语种
verbose=True
)
# 输出结果
print(result["text"]) # 转录或翻译文本(默认往英文翻译)
参数说明:
model: 指定模型版本(如"large-v3"), 首次运行时会自动下载模型权重.device: 指定设备("cuda"或"cpu"), GPU 可显著加速推理.language: 指定输入音频的语言(如"zh"表示中文), 若不指定, 模型会自动检测语种.task: 可选择"transcribe"(转录)或"translate"(翻译).
处理长音频:
- 若音频超过
30秒, 模型会自动分块处理, 无需手动分割.
2. 通过 HuggingFace transformers 库进行语音识别
安装依赖
1
2
3
pip install transformers
pip install torch
pip install soundfile # 用于加载音频文件
代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from transformers import WhisperProcessor, WhisperForConditionalGeneration
import soundfile as sf
import torch
# 加载处理器和模型
processor = WhisperProcessor.from_pretrained("openai/whisper-large-v3")
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-large-v3")
model.to("cuda") # 使用 GPU 加速
# 加载音频文件
audio_path = "your_audio_file.wav" # 替换为实际文件路径
audio_input, sample_rate = sf.read(audio_path)
# 预处理音频(转换为 Log-Mel 频谱)
input_features = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_features
input_features = input_features.to("cuda") # 将输入数据移至 GPU
# 生成转录结果
with torch.no_grad():
predicted_ids = model.generate(input_features, language="zh", task="transcribe")
# 解码为文本
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
print(transcription) # 打印转录文本
参数说明:
processor: 负责音频预处理(如特征提取和标记化).model: Whisper-large-v3 模型, 支持转录和翻译任务.language: 指定输入音频的语言(如"zh"表示中文).task: 可选择"transcribe"(转录)或"translate"(翻译).
3. 对比
openai-whisper库: 简单易用, 适合快速部署.- Hugging Face
transformers库: 灵活性高, 支持自定义预处理和后处理.
四、性能优化建议
使用
GPU加速、批处理和量化技术可提升效率.
- GPU 加速
使用GPU(如NVIDIA A100)可显著提升推理速度. 确保安装支持GPU的PyTorch版本:1
$ pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
- 批处理
若需处理多个音频文件, 可将输入数据打包为批次 (batch) 以提高效率:1 2
# 假设 audio_list 是多个音频文件的列表 input_features = processor(audio_list, sampling_rate=sample_rate, return_tensors="pt", padding=True).input_features
- 量化与蒸馏
若需在cpu或低资源设备上运行, 可尝试量化(如8-bit)或使用蒸馏版模型(如Whisper-small).