Softmax 函数详解
函数简介
在数学(尤其是概率论及其相关学科)领域中,
Softmax函数, 或称归一化指数函数, 是 逻辑斯谛函数 的一种推广.
Softmax 函数是一种 多元非线性 激活函数, 常用于求解输出结果的概率分布. 与其它单变量非线性激活函数 (例如 ReLU, Tanh, Sigmoid 等) 不属于同一类别.
-
多元也就意味着没有一个准确的曲线可以完整表达该函数. -
非线性意味着函数的变化不满足比例性 和叠加性, 即输入与输出之间不呈直线关系. 大多数自然现象本质上是非线性的.
函数功能
Softmax 能将一个含任意实数的 K维 向量 ${\displaystyle \mathbf{z}}$ “压缩” 到另一个 K维 实向量 ${\displaystyle \sigma (\mathbf{z})}$ 中, 使得每一个元素的范围都在 ${\displaystyle (0, 1)}$ 之间, 并且所有元素的和为 1.
给定单个 5维 输入向量 $\mathbf{z}$, 经过 softmax 函数得到另一个 5维 向量, 示例如下:
向量 $\mathbf{z}$ 的 shape 为 (5,). 在多分类任务中, shape 中的 5 可以表示五种分类, 经过 Softmax 之后, 其中的每一个元素表示输入数据属于该分类的概率大小.
补充:
1
2
3
4
数据进行归一化,转化为一个(0,1)之间的数值,这些数值可以被当做概率分布,用来作为多分类的目标预测值。Softmax函数一般作为神经网络的最后一层,接受来自上一层网络的输入值,然后将其转化为概率。
由于指数函数曲线是呈现递增趋势,即斜率逐渐增大。这种函数曲线能够将输出的数值拉开距离。
在深度学习中通常使用反向传播求解梯度进而使用梯度下降进行参数更新的过程,而指数函数在求导的时候比较方便。
指数函数的曲线斜率逐渐增大虽然能够将输出值拉开距离,但是也带来了缺点,当Z值非常大的话,计算得到的数值也会变的非常大,数值可能会溢出。有对应的优化方法解决这个问题。
函数曲线 (2D 数据可视化)
绘制 2D+ 的 Softmax 函数曲线可能并不容易, 但绘制 2D-Softmax 函数曲线用来说明问题却很简单.
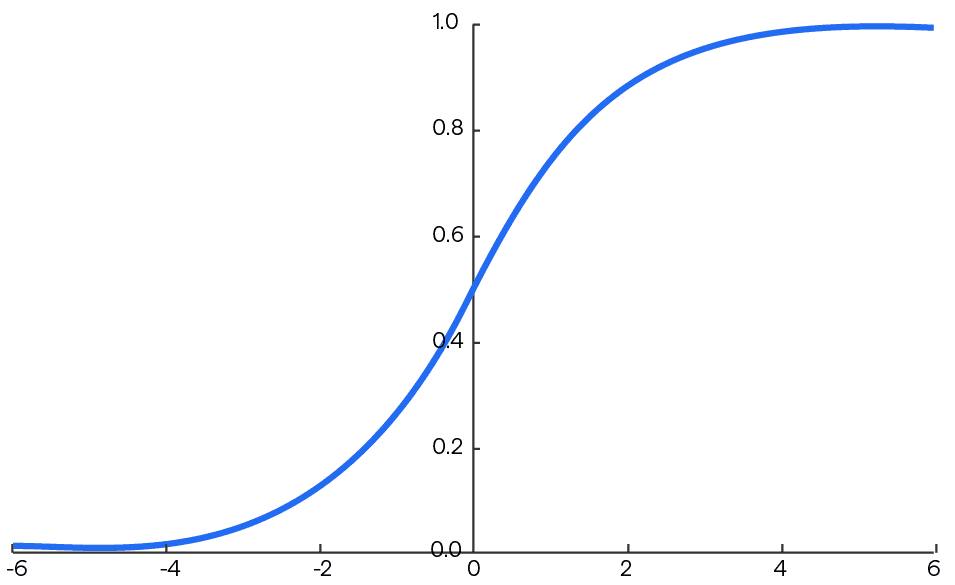
从上图可以直观得到以下信息:
softmax函数的值域范围在0~1之间- 当自变量趋于正负无穷时, 函数的导数或者说梯度接近
0
函数定义
\[\sigma(\vec{z})_{i} = \frac{e^{z_i}}{\sum_{j=1}^Ke^{z_j}}\]其中:
-
$\sigma$ = softmax
-
$\vec{z}$ = input vector
-
$e^{z_{i}}$ = standard exponential function for input vector
-
$i$ = input vector 中的第
i个元素 -
$K$ = number of classes in the multi-class classifier
-
$e^{z_{j}}$ = standard exponential function for output vector
-
$j$ = 多分类任务中第
j个分类
计算过程
以 input_vector (即上文公式中的 $\vec{z}$) 5D 向量 [1, 2, 3, 4, 5] 作为输入讲解如何计算 Softmax.
首先对 input_vector 中每个元素计算 e 指数.
- 例如取第一个元素: $input\_vector[0]$ 为 1
- $e^{z_i}$ 当 $i=0$ 时, $e^{input\_vector[0]}$ 即 $e^1$ 的计算结果为 $e$
同理可以计算出其他元素对应的 e 指数结果:
- $i=1$ 时, 结果为 $e^2$
- $i=2$ 时, 结果为 $e^3$
- $i=3$ 时, 结果为 $e^4$
- $i=4$ 时, 结果为 $e^5$
计算 input_vector 中所有元素对应的 e 指数之和.
- $e\_sum = e^1 + e^2 + e^3 + e^4 + e^5$
结果为 233.2041839862982.
计算 softmax 结果:
- $e^1 / e\_sum$ 即
0.011656230956039607 - $e^2 / e\_sum$ 即
0.03168492079612427 - $e^3 / e\_sum$ 即
0.0861285444362687 - $e^4 / e\_sum$ 即
0.23412165725273662 - $e^5 / e\_sum$ 即
0.6364086465588308
最终 input_vector 对应的 Softmax 结果为 [0.01165623, 0.03168492, 0.08612854, 0.23412166, 0.63640865].
输入示例
分别以 numpy 实现和 torch 实现进行比较, 可以发现二者的输出结果一致 (注意: torch 输出做了截断).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import numpy as np
def softmax(z):
return np.exp(z) / np.sum(np.exp(z), axis=0, keepdims=True)
vector_z = np.array([1, 2, 3, 4, 5])
print(f"softmax(vector_z)=", softmax(vector_z))
# 输出
# softmax(vector_z)= [0.01165623 0.03168492 0.08612854 0.23412166 0.63640865]
import torch
import torch.nn.functional as F
vector_z = torch.from_numpy(vector_z).to(dtype=torch.float32)
print(f"softmax(vector_z)=", F.softmax(vector_z, dim=0))
# 输出
# softmax(vector_z)= tensor([0.0117, 0.0317, 0.0861, 0.2341, 0.6364])
设计原理
为什么选择 指数函数 $e^{z_i}$ 而非其它可实现归一化的方案? 核心有三点:
- 放大差异: 指数函数的增长速率远超线性函数, 能将原始 logits 之间的微小差距显著拉大, 使模型输出的概率分布更加”锐利”, 有利于分类决策.
- 保证非负: $e^x > 0$ 对所有实数 $x$ 成立, 天然满足概率的非负性要求, 无需额外裁剪.
- 求导友好: 指数函数的导数等于自身 ($\frac{d}{dx}e^x = e^x$), 使得 Softmax 的雅可比矩阵可以用自身输出简洁表达 (见下文求导过程), 有利于反向传播的高效计算.
Softmax 求导过程
Softmax 函数求导过程即是数学中常见的求偏导数的过程, 对于多变量求偏导时, 除了该变量本身, 其它量皆可看作是常量 (即导数为 0).
将 Softmax 函数记为 $S_i$, 则导数为:
求 $\sigma(\vec{z})_{i}$ 对 $z_j$ 的偏导数如下:
\[\frac{\partial{S_i} }{\partial{z_j}}\]需要分两种情况讨论:
-
情况 1: $i$ 和 $j$ 相同, 即 $i == j$. 此时需要将 $z_i$ 视为变量, 按照复合函数求导规则, 求偏导如下:
\[\frac{\partial{S_i} }{\partial{z_j}} = \frac{e^{z_i}}{\sum_{j=1}^Ke^{z_j}} - e^{z_i} \cdot {\frac{1}{\sum_{j=1}^Ke^{z_j}}}^2 \cdot e^{z_j}\]由于 $i == j$, 故 $z_i == z_j$:
\[\frac{\partial{S_i} }{\partial{z_j}} = \frac{e^{z_i}}{\sum_{j=1}^Ke^{z_j}} - {\frac{e^{z_i}}{\sum_{j=1}^Ke^{z_j}}}^2\]将
\[S_i' = S_i - S_i^2 = S_i(1 - S_i) = S_i(1 - S_j)\]Softmax函数记为 $S_i$, 则: -
情况 2: $i$ 和 $j$ 不同, 此时需要将 $z_i$ 视为常量, 按照复合函数求导规则, 求偏导如下:
\[\frac{\partial{S_i} }{\partial{z_j}} = - e^{z_i} \cdot \frac{1}{(\sum_{j=1}^Ke^{z_j})^2} \cdot e^{z_j}\]由于 $z_i i != z_j$:
\[\begin{align} \frac{\partial{S_i} }{\partial{z_j}} =& - \frac{e^{z_i} \cdot e^{z_j}}{(\sum_{j=1}^Ke^{z_j})^2} \\ =& - \frac{e^{z_i}}{\sum_{j=1}^Ke^{z_j}} \cdot \frac{e^{z_j}}{\sum_{j=1}^Ke^{z_j}} \end{align}\]将
\[S_i' = - S_i \cdot S_j\]Softmax函数记为 $S_i$, 则